15.Linux0.12中如何创建进程-内存篇
作者:小牛呼噜噜 ,首发于公众号「小牛呼噜噜」
{kind=link}
哈喽,大家好呀,我是呼噜噜,最近较长一段时间都没有更新,都在写这篇文章,本文继续沿着系统进程的创建,将涉及到内存管理都串起来梳理一遍,干货满满
在之前的一篇文章在Linux0.12中如何创建进程?我们讲解了Linux0.12中如何创建进程
copy_process
我们继续以进程的创建函数fork为切入点,fork是个系统调用,我们知道执行fork函数,其实调用系统中断0x80,跳转到绑定的_system_call中,继而去执行sys_call_table跳转表中的第2项sys_fork函数
sys_fork汇编源码:
// /kernel/sys_call.s
.align 2
_sys_fork:
call _find_empty_process # 为新进程取得进程号 last_pid
testl %eax,%eax # eax保存的是任务号,即任务数组下标值,若返回负数则退出
js 1f
push %gs
pushl %esi
pushl %edi
pushl %ebp
pushl %eax
call _copy_process # 调用 C 函数 copy_process()
addl $20,%esp # 丢弃这里所有压栈内容
1: ret
sys_fork函数会去调用find_empty_process,为新进程取得进程号last_pid。接着还会继续调用C函数copy_process,通过复制父进程信息来创建新进程。copy_process源码:
// /kernel/fork.c
/*
* Ok, this is the main fork-routine.
* 它复制系统进程信息(task[n])并且设置必要的寄存器。它还整个地复制数据段
*/
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx, long orig_eax,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page(); //为新任务数据结构分配内存(如果分配出错,则返回出错码并退出)。
if (!p)
return -EAGAIN;
task[nr] = p;// 将新任务结构指针放入任务数组中。其中nr 为任务号,由前面find_empty_process()返回
*p = *current; //注意!这样做不会复制超级用户的堆栈(只复制当前进程内容)
p->state = TASK_UNINTERRUPTIBLE; // 将新进程的状态先置为不可中断等待状态。以防止内核调度其执行
p->pid = last_pid; // 新进程号。由前面调用find_empty_process()得到。
p->counter = p->priority; // 运行时间片值(嘀嗒数)
p->signal = 0; // 信号位图。
p->alarm = 0; // 报警定时值(嘀嗒数)
p->leader = 0; /* 进程的领导权是不能继承的 */
p->utime = p->stime = 0; //用户态时间和核心态运行时间。
p->cutime = p->cstime = 0; // 子进程用户态和核心态运行时间
p->start_time = jiffies; // 进程开始运行时间(当前时间滴答数)
//接下来修改任务状态段 TSS 内容
p->tss.back_link = 0;
p->tss.esp0 = PAGE_SIZE + (long) p; // 任务内核态栈指针
p->tss.ss0 = 0x10; // 内核态栈的段选择符(与内核数据段相同)
p->tss.eip = eip; // 指令代码指针!!!,需要注意的是:子进程的EIP同父进程一样,所以两次fork返回时,父子进程都从这条指令开始执行
p->tss.eflags = eflags; // 标志寄存器
p->tss.eax = 0; // 这是当fork()返回时新进程会返回0的原因所在
p->tss.ecx = ecx;
p->tss.edx = edx;
p->tss.ebx = ebx;
p->tss.esp = esp;
p->tss.ebp = ebp;
p->tss.esi = esi;
p->tss.edi = edi;
p->tss.es = es & 0xffff; // 段寄存器仅 16 位有效
p->tss.cs = cs & 0xffff;
p->tss.ss = ss & 0xffff;
p->tss.ds = ds & 0xffff;
p->tss.fs = fs & 0xffff;
p->tss.gs = gs & 0xffff;
p->tss.ldt = _LDT(nr); // 任务 LDT 描述符的选择符(LDT 描述符在 GDT 中)
p->tss.trace_bitmap = 0x80000000;
if (last_task_used_math == current) //如果当前任务使用了协处理器,就保存其上下文
__asm__("clts ; fnsave %0 ; frstor %0"::"m" (p->tss.i387));
//接下来复制进程页表。即在线性地址空间中设置新任务代码段和数据段描述符中的基址和限长,并复制页表
if (copy_mem(nr,p)) { //如果出错(返回值不是 0),则
task[nr] = NULL; //复位任务数组中相应项
free_page((long) p);//并释放为新任务分配的用于任务结构的内存页
return -EAGAIN;
}
// 如果父进程中有文件是打开的,则将对应文件的打开次数增1
for (i=0; i<NR_OPEN;i++)
if (f=p->filp[i])
f->f_count++;
// 将当前进程(父进程)的pwd, root 和executable 引用次数均增1
if (current->pwd)
current->pwd->i_count++;
if (current->root)
current->root->i_count++;
if (current->executable)
current->executable->i_count++;
if (current->library)
current->library->i_count++;
// 在GDT 中设置新任务的TSS 和LDT 描述符项,数据从task 结构中取。
// 请注意,在任务切换时,任务寄存器 TR 会由 CPU 自动加载
set_tss_desc(gdt+(nr<<1)+FIRST_TSS_ENTRY,&(p->tss));
set_ldt_desc(gdt+(nr<<1)+FIRST_LDT_ENTRY,&(p->ldt));
p->p_pptr = current; // 设置新进程的父进程指针
p->p_cptr = 0; // 复位新进程的最新子进程指针
p->p_ysptr = 0; // 复位新进程的比邻年轻兄弟进程指针
p->p_osptr = current->p_cptr; // 设置新进程的比邻老兄兄弟进程指针
if (p->p_osptr) // 若新进程有老兄兄弟进程,则让其年轻进程兄弟指针指向新进程
p->p_osptr->p_ysptr = p;
current->p_cptr = p; // 让当前进程最新子进程指针指向新进程
p->state = TASK_RUNNING; /* 最后再将新任务设置成可运行状态,以防万一 */
return last_pid; // 返回新进程号(与任务号是不同的)
}
前文在Linux0.12中如何创建进程?我们已经详细讲解了copy_process函数的内部操作与机制。我们这里不再赘述,本文专注于内存相关的机制
get_free_page
copy_process中get_free_page函数的功能,主要是为新任务的数据结构task[n],去主内存中申请分配一页空闲的内存,并返回这个页的地址
我们先来看下get_free_page的源码:
/*
* Get physical address of first (actually last :-) free page, and mark it
* used. If no free pages left, return 0.
*/
//在主内存区中申请取得一空闲物理页面
unsigned long get_free_page(void)
{
register unsigned long __res asm("ax");
repeat:
__asm__("std ; repne ; scasb\n\t" // 方向位置位,将al(0)与对应每个页面的(di)内容比较,
"jne 1f\n\t" // 如果没有等于0 的字节,则跳转结束(返回0)
"movb $1,1(%%edi)\n\t" // 将对应页面的内存映像位,置为1!,1 =>[1+edi]
"sall $12,%%ecx\n\t" //ecx的值左移12位,也就是页面数*4K=相对页面起始地址!
"addl %2,%%ecx\n\t" //再加上低端内存地址(因为传入地址仅是主内存的),得页面实际物理起始地址
"movl %%ecx,%%edx\n\t" //将页面实际起始地址edx 寄存器
"movl $1024,%%ecx\n\t" //寄存器 ecx 置计数值 1024
"leal 4092(%%edx),%%edi\n\t" // 将 4092+edx 的位置edi(该页面的末端,即当前物理页最后一项的地址),其中4096 = 4096-4 = 1023*4 = (1024-1)*4
"rep ; stosl\n\t" // 将edi所指内存清零(反方向,即将该页面清零);需要注意的是,stosl每次只能将4个bit清零
"movl %%edx,%%eax\n" // 将页面起始地址eax(返回值)
"1:"
:"=a" (__res) //参数装配
:"0" (0),"i" (LOW_MEM),"c" (PAGING_PAGES),
"D" (mem_map+PAGING_PAGES-1)
:"di","cx","dx");
if (__res >= HIGH_MEMORY) //页面地址大于实际内存容量则重新寻找
goto repeat;
if (!__res && swap_out()) //若没得到空闲页面则执行交换处理,并重新查找
goto repeat;
return __res; // 返回空闲物理页面地址。
}
这块主要和mem_map有关,我们知道Linux0.12直接通过mem_map这个数组来直接管理内存,mem_map叫做页面映射数组,记录主内存(1M~16M),每个字节描述一个内存页的占用状态(即占用次数),比如哪些内存页被占用了,哪些内存页空闲,从而对****内存分页进行管理,详情可见之前的文章Linux0.12内核源码解读(6)-main.c

另外内存的管理是以内存页为单位的,这是由于内存采用了分页管理机制,页的大小固定为4K,即地址连续的4K字节物理内存

std ; repne ; scasb这条汇编语句就是倒序(方向),循环在字符串中搜索特定的字符;其他的汇编语句大家仔细看注释(里面的细节非常多),我们不再赘述

再结合已经装入寄存器的参数,我们可以得出get_free_page函数它会去寻找mem_map中值为0的项(即空闲的页),将其置为1来表示占用,然后算出该项对应的物理内存页的起始地址,并将内存页清零,最后将该页的地址返回
当
mem_map项的值为 100 时,表示已被完全占用,不能再被分配
如果得到的内存页地址大于实际物理内存容量则重新寻找。如果没有找到空闲页面,则去调用执行交换处理,并重新查找。最后返回空闲内存页的起始地址
还需要注意的是,内核调用get_free_page这个函数,只是找到在主内存区的一页空闲物理页, 与每个进程的线性地址无关,并没有映射到某个进程的地址空间中去,当然对于Linux0.12版的内核而言,也并不需要映射到物理地址空间,因为低端内存16M之内已经进行了完全映射,逻辑地址==线性地址==物理地址,所以get_free_page返回的地址,虽然是该空闲页的线性地址,但也是其物理内存起始地址

copy_mem
我们接着往下看copy_process函数,下一个和内存管理有关的函数copy_mem(nr,p):
// /kernel/fork.c
// copy_process
//接下来复制进程页表。即在线性地址空间中设置新任务代码段和数据段描述符中的基址和限长,并复制页表
if (copy_mem(nr,p)) { //如果出错(返回值不是 0),则
task[nr] = NULL; //复位任务数组中相应项
free_page((long) p);//并释放为新任务分配的用于任务结构的内存页
return -EAGAIN;
}
...
//复制内存页表
int copy_mem(int nr,struct task_struct * p)
{
unsigned long old_data_base,new_data_base,data_limit;
unsigned long old_code_base,new_code_base,code_limit;
//取当前进程局部描述符表中 代码段描述符中的段限长(字节数);0x0f 是代码段选择符
code_limit=get_limit(0x0f);
//取当前进程局部描述符表中 数据段描述符项中的段限长(字节数);0x17 是数据段选择符
data_limit=get_limit(0x17);
//接着取当前进程代码段和数据段在线性地址空间中的基地址,64MB对齐!
old_code_base = get_base(current->ldt[1]);
old_data_base = get_base(current->ldt[2]);
//由于 Linux 0.12 内核还不支持代码和数据段分立的情况,所以还需以下判断
if (old_data_base != old_code_base)
panic("We don't support separate I&D");
if (data_limit < code_limit)//数据段长度 也不能小于 代码段长度
panic("Bad data_limit");
//后设置新建进程 在线性地址空间中的基地址(等于 64MB * 其任务号)
new_data_base = new_code_base = nr * TASK_SIZE;
p->start_code = new_code_base;
set_base(p->ldt[1],new_code_base);//设置代码段描述符中基地址
set_base(p->ldt[2],new_data_base);//设置数据段描述符中基地址
//接着设置新进程的页目录表项和页表项,即复制当前进程(父进程)的页目录表项和页表项
if (copy_page_tables(old_data_base,new_data_base,data_limit)) {
//如果出错,则释放刚申请的页表项
free_page_tables(new_data_base,data_limit);
return -ENOMEM;
}
return 0;
}
copy_mem函数,其参数nr是新任务号,p是新任务数据结构指针。首先获取当前进程局部描述符表中代码段描述符中的段限长、数据段描述符项中的段限长;接着取当前进程代码段和数据段在线性地址空间中的基地址;然后设置新进程(任务)代码段和数据段描述符中的基址,段限长暂未设置,也无需设置,并复制内存页表
其中TASK_SIZE=0x04000000,也就是64M,这个对应着Linux0.12为每个进程默认分配64M的虚拟空间(也就是线性地址空间),所以新基址=任务号*64M;但分配的实际物理内存大小并不是,这个需要敲黑板!下文我们会详细讲解的

上述的各个参数都和LDT段描述符有关,下面就是80386段描述符的结构图:

段基地址base,一个32位值,表示段segment在内存中的起始地址
段界限limit,20位值,用于指定段的长度,表示最大可寻址单元;通过G来区分是以字节(Byte)为单位,还是以4KB为单位
访问权限DP,表示段描述符特权级
另外get_limit、get_base、set_base的源码如下:
// /include/linux/sched.h
//设置位于地址 addr 处描述符中的各基地址字段(基地址是 base)
#define _set_base(addr,base) \
__asm__("movw %%dx,%0\n\t" \ // 基址 base 低 16 位(位 15-0)->[addr+2]
"rorl $16,%%edx\n\t" \ // edx 中基址高 16 位(位 31-16)->dx
"movb %%dl,%1\n\t" \ // 基址高 16 位中的低 8 位(位 23-16)->[addr+4]
"movb %%dh,%2" \ // 基址高 16 位中的高 8 位(位 31-24)->[addr+7]
::"m" (*((addr)+2)), \
"m" (*((addr)+4)), \
"m" (*((addr)+7)), \
"d" (base) \
:"dx") // 告诉 gcc 编译器 edx 寄存器中的值已被嵌入汇编程序改变了
// 从地址addr 处描述符中取段基地址。功能与_set_base()正好相反。
// edx - 存放基地址(__base);%1 - 地址addr 偏移2;%2 - 地址addr 偏移4;%3 - addr 偏移7。
#define _get_base(addr) ({\
unsigned long __base; \
__asm__( "movb %3,%%dh\n\t" \ // 取[addr+7]处基址高16 位的高8 位(位31-24)??dh。
"movb %2,%%dl\n\t" \ // 取[addr+4]处基址高16 位的低8 位(位23-16)??dl。
"shll $16,%%edx\n\t" \ // 基地址高16 位移到edx 中高16 位处。
"movw %1,%%dx" \ // 取[addr+2]处基址低16 位(位15-0)??dx。
:"=d" (__base) \ // 从而edx 中含有32 位的段基地址。
:"m" (*((addr) + 2)), "m" (*((addr) + 4)), "m" (*((addr) + 7)));
__base;
}
//取段选择符 segment 指定的描述符中的段限长值。
#define get_limit(segment) ({ \
unsigned long __limit; \
__asm__("lsll %1,%0\n\tincl %0":"=r" (__limit):"r" (segment)); \
__limit;})
copy_page_tables
copy_mem函数的核心功能复制内存页表,主要由copy_page_tables函数来实现
/*
* 好了,下面是内存管理mm 中最为复杂的程序之一。它通过只复制内存页面
* 来拷贝一定范围内线性地址中的内容。希望代码中没有错误,因为我不想
* 再调试这块代码了?。
*
* 注意!我们并不是仅复制任何内存块 - 内存块的地址需要是4Mb 的倍数(正好
* 一个页目录项对应的内存大小),因为这样处理可使函数很简单。不管怎样,
* 它仅被fork()使用(fork.c 第56 行)。
*
* 注意2!!当from==0 时,是在为第一次fork()调用复制内核空间。此时我们
* 不想复制整个页目录项对应的内存,因为这样做会导致内存严重的浪费 - 我们
* 只复制头160 个页面 - 对应640kB。即使是复制这些页面也已经超出我们的需求,
* 但这不会占用更多的内存 - 在低1Mb 内存范围内我们不执行写时复制操作,所以
* 这些页面可以与内核共享。因此这是nr=xxxx 的特殊情况(nr 在程序中指页面数)。
*/
//复制指定线性地址和长度(页表个数)内存对应的页目录项和页表
int copy_page_tables(unsigned long from,unsigned long to,long size)// 参数 from、to 是线性地址,size 是需要复制(共享)的内存长度,单位是字节
{
unsigned long * from_page_table; //用于管理源页表
unsigned long * to_page_table; //用于管理目的页表
unsigned long this_page; //用于保存页表
unsigned long * from_dir, * to_dir; //用于管理源页目录项,目的页目录项
unsigned long new_page; //新申请的页
unsigned long nr; //页表项个数
//需要确保源地址和目的地址都需要在4Mb内存边界地址上,不然恐慌
if ((from&0x3fffff) || (to&0x3fffff))
panic("copy_page_tables called with wrong alignment");
//获取源页目录项指针 from_dir
from_dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */
//目的页目录项指针 to_dir
to_dir = (unsigned long *) ((to>>20) & 0xffc);
//需要复制的页表个数 size
size = ((unsigned) (size+0x3fffff)) >> 22;
//下面开始对每个页目录项依次申请 1 页内存来保存对应的页表,并且开始页表项复制操作
for( ; size-->0 ; from_dir++,to_dir++) {
if (1 & *to_dir)//如果目的目录项指定的页表已经存在(P=1),则出错死机
panic("copy_page_tables: already exist");
if (!(1 & *from_dir))//如果源目录项无效,即指定的页表不存在(P=0),则继续循环处理下一个页目录项
continue;
//获取源页中页表地址 from_page_table
from_page_table = (unsigned long *) (0xfffff000 & *from_dir);
//保存目的目录项对应的页表,需要在主内存区中申请 1 页空闲内存页
if (!(to_page_table = (unsigned long *) get_free_page()))
return -1; /* Out of memory, see freeing */
//设置目的目录项信息:把最后 3 位置位,即当前目的目录项“或”上 7,表示对应
//页表映射的内存页面是用户级的,并且可读写、存在(Usr, R/W, Present)
*to_dir = ((unsigned long) to_page_table) | 7;
//如果是在内核空间,则仅需复制头 160 页对应的页表项
// (nr= 160),对应于开始 640KB 物理内存。否则需要复制一个页表中的所有 1024 个页表项
// (nr= 1024),可映射 4MB 物理内存。
nr = (from==0)?0xA0:1024;//如果是0地址(第一次fork),只拷贝160页,否则拷贝1024页
//一个页目录表管理1024个页目录项
//一个页表管理1024个页表项
//一个页表项管理有4K物理地址
//此时对于当前页表,开始循环复制指定的 nr 个内存页面表项。先取出源页表项内容,如果
// 当前源页面没有使用(项内容为 0),则不用复制该表项,继续处理下一项
for ( ; nr-- > 0 ; from_page_table++,to_page_table++) {
this_page = *from_page_table;
if (!this_page)
continue;
//如果该表项有内容,但是其存在位 P=0,则该表项对应的页面可能在交换设备中。于是先申
// 请 1 页内存,并从交换设备中读入该页面(若交换设备中有的话)
if (!(1 & this_page)) {
if (!(new_page = get_free_page()))
return -1;
read_swap_page(this_page>>1, (char *) new_page);
*to_page_table = this_page;
//修改源页表项内容指向该新申请的内存页,并设置表项标志为“页面脏”
// 加上7,表示可读写。然后继续处理下一页表项
*from_page_table = new_page | (PAGE_DIRTY | 7);
continue;
}
//否则复位页表项中R/W读写位(位 1 置 0),即让页表项对应的内存页面只读!!!
this_page &= ~2;
//然后将该页表项复制到目的页表中
*to_page_table = this_page;
//如果该页表项所指物理页面的地址在 1MB 以上,则需要设置内存页面映射数组 mem_map[]
//主要因为物理内存 1MB (LOW_MEM) 并不采用用户态下的分页系统来寻址,而是按照“段(选择子)+偏移”的方法。1MB 以上,才采用分页
if (this_page > LOW_MEM) {
*from_page_table = this_page; // 令源页表项也只读!!!;因为现在开始已有两个进程共用内存
// 区了。若其中 1 个进程需要进行写操作,则可以通过页异常写保护处理为执行写操作的进
// 程分配 1 页新空闲页面,也即进行写时复制(copy on write)操作
this_page -= LOW_MEM; //取相对主内存的偏移地址
this_page >>= 12; //取主内存管理数组索引
mem_map[this_page]++; //物理页的引用次数加1,表明该页又被一个进程给使用了
}
}
}
invalidate(); // 刷新cpu页缓冲器保存以上的修改
return 0;
}
一上来判断if ((from&0x3fffff) || (to&0x3fffff)),是为了确保源地址和目的地址都需要在4MB内存边界地址上,0x3fffff转换为32位的二进制就是前10为0,后22为1,其实就是为了保证from和to的低22位是否全部为0,这样才能确保后续循环中,从一个页表的第1项开始完整地复制页表项 ,而不会遗漏。紧接着size = ((unsigned) (size+0x3fffff)) >> 22,确保页目录项数是4M的倍数,也就是要复制的页表数
需要注意一下,from_dir = (unsigned long *) ((from>>20) & 0xffc);这边右移20位,是因为系统初始化时,GDT是从存放在0地址处,也就是页目录表的起始地址是0, 每项大小4B,共1024项,页目录表共占4K字节(0x1000)
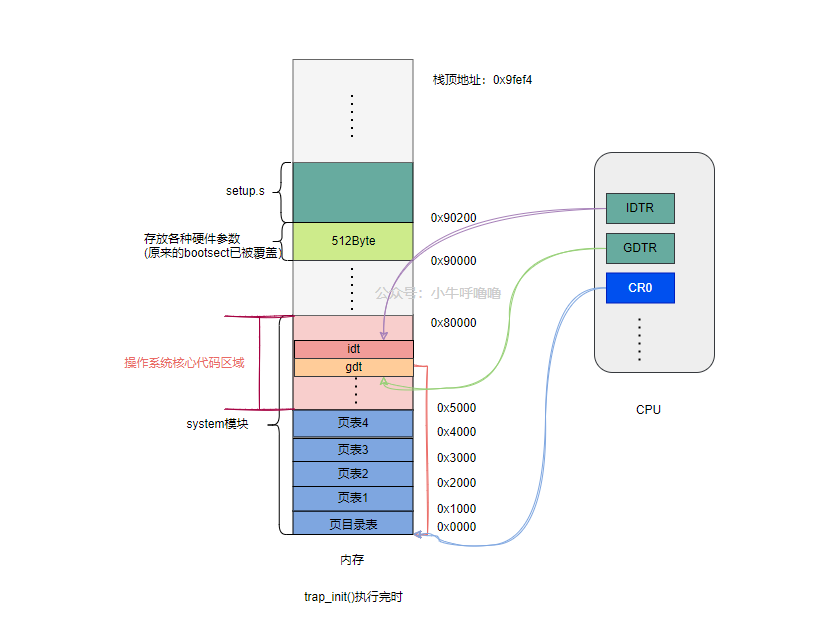
页目录号和对应页目录地址也有了对照关系:页目录号*每项大小4=页目录地址,即页目录号<<4
又因为开启分页后,线性地址addr(32位)的前10位是页目录索引,即addr>>22(取高十位)
那么对应的页目录地址 = (addr>>22) *4 =(addr >>20)
所以这里from地址右移20位,再和0xffc相与确保不能超出1024个页目录项的范围,最后再强转成源页目录项的地址指针。真是处处都是细节~

在Linux0.12中已经开启了分页,通过页目录项和页表项,可以寻址到指定物理内存页,具体详情可见图解CPU的实模式与保护模式,了解分页机制里面的页目录表、页表、页之间的关系

逻辑地址、线性地址、物理地址:逻辑地址(即OS启动时开启分页,后面的所有代码中的地址)通过分段机制得到线性地址,线性地址通过分页后的页目录项和页表项,得到实际的物理地址
copy_page_tables这个函数是Linux0.12中内存管理的最核心的代码之一!它会复制指定线性地址和长度内存对应的页目录项和页表项,来作为新进程的页目录表项和页表项,其中新的页表需要申请新的内存页来存放。注意,这里仅仅是复制父进程的页目录项和页表项,并没有整个复制父进程的进程空间!
其中this_page &= ~2;设置页表项的读写权限为"只读",将其值赋给*to_page_table目标页表项,这会导致目标页表项就跟源目标页表项指向同一个页。接着如果当this_page > LOW_MEM,还要将该值再重新赋给*from_page_table,从而被复制的页目录和页表对应的原物理内存页面区被两套页表映射而共享使用,权限是只读不能写,来保护共享空间,防止脏读

此后子进程共享父进程的内存页面,直到当其中有一个进程执行写操作时(对共享空间写会导致写保护异常,CPU会去执行写保护异常处理函数do_wp_page),才分配新的物理内存页。这个也被叫做,写时复制copy on write,这样可以极大地节约内存空间和减少创建进程时的开销!高效且非常巧妙

我们再回到copy_process函数处,正常情况下copy_page_tables函数返回0;否则表示出错,则调用free_page_tables函数来释放刚申请的页表项
free_page_tables与free_page
接着上一小节, free_page_tables()用于释放指定线性地址和长度(页表个数)对应的物理内存页,和
copy_page_tables是相反操作:
/*
* This function frees a continuos block of page tables, as needed
* by 'exit()'. As does copy_page_tables(), this handles only 4Mb blocks.
*/
//根据指定的线性地址和限长(页表个数),释放内存块并置表项空闲
int free_page_tables(unsigned long from,unsigned long size)
{
unsigned long *pg_table;
unsigned long * dir, nr;
// 判断参数from的线性基地址是否在4MB边界处、即4M的倍数,比如4MB、8MB、12MB
if (from & 0x3fffff)
panic("free_page_tables called with wrong alignment");
if (!from)
panic("Trying to free up swapper memory space");
// 释放的页表个数,页目录项数
size = (size + 0x3fffff) >> 22;
//获得线性基地址对应的起始目录项地址指针
dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */
for ( ; size-->0 ; dir++) {
if (!(1 & *dir))
continue;
pg_table = (unsigned long *) (0xfffff000 & *dir);// 取页表地址
for (nr=0 ; nr<1024 ; nr++) {
if (*pg_table) { // 若所指页表项内容不为0
if (1 & *pg_table) // 若该项有效,则释放对应页
free_page(0xfffff000 & *pg_table);
else
swap_free(*pg_table >> 1); // 否则释放交换设备中对应页
*pg_table = 0; // 该页表项内容清零
}
pg_table++; // 指向页表中下一项
}
free_page(0xfffff000 & *dir); // 释放该表所占内存页面
*dir = 0; // 对应页表的目录项清零
}
invalidate(); // 刷新CPU页变换高速缓冲
return 0;
}
free_page_tables函数具体流程是,先计算在页目录表中所占用的目录项数(即页表个数),并计算对应的起始目录项号。然后从对应起始目录项开始,循环释放所占用的所有目录项,接着释放对应目录项所指的页表中的所有页表项和相应的物理内存页;同时并将页表项和页目录项的内容清零
期间会调用free_page去释放地址对应物理页,这里的释放并不是直接操作物理内存页,而是将mem_map中对应项的值减1。这里也会涉及到内存交换,这个是Linux0.12新增的功能,暂不展开讲,我们以后有机会再细究其细节
free_page函数主要功能是,释放指定物理地址的一页内存,其中物理地址在1M以下的内存空间,它是用于内核程序和缓冲,是不能被作为分配页面的内存空间的,所以参数地址addr需要确保是大于1M的
// /mm/memory.c
/*
* Free a page of memory at physical address 'addr'. Used by
* 'free_page_tables()'
*/
//释放物理地址'addr'处的一页内存
void free_page(unsigned long addr)
{
// 当物理地址addr小于内存低端(1MB),不处理
if (addr < LOW_MEM) return;
//如果物理地址addr >= 系统所含物理内存最高端,则显示出错信息并且内核停止工作
if (addr >= HIGH_MEMORY)
panic("trying to free nonexistent page");
// 获取对应页面
addr -= LOW_MEM;
//根据这个物理地址换算出从内存低端开始计起的内存页面号。页面号 = (addr – LOW_MEM)/4096
addr >>= 12;
if (mem_map[addr]--) return;
//走到这,表示内核出问题,置0标记为空闲
mem_map[addr]=0;
panic("trying to free free page");
}
页异常/页中断
在Linux0.12中,当CPU开启分页,若出现页访问权限不足或者页不存在,便会触发页异常(页中断),中断号14,在异常中断处理程序处理完后,返回原点重新执行先前触发异常的指令
从之前陷阱门初始化中的函数set_trap_gate(14,&page_fault),我们知道,中断描述符表第14项存放的是page_fault程序的地址,也就是触发中断14,CPU会自动跳转该函数的地址,去执行函数page_fault
// /mm/page.s
_page_fault:
xchgl %eax,(%esp) // 交换两个寄存器的值,esp指向的位置保存了错误码
pushl %ecx // 压栈
pushl %edx
push %ds
push %es
push %fs
movl $0x10,%edx // 内核数据段描述符
mov %dx,%ds
mov %dx,%es
mov %dx,%fs
movl %cr2,%edx // 如果是缺页异常,将引起缺页的线性地址存入cr2
// 将线性地址和错误码 压入栈中,作为参数
pushl %edx
pushl %eax
testl $1,%eax//判断 页存在标志P(位0),如果不是缺页引起的异常则跳转
jne 1f
call _do_no_page //调用缺页处理函数
jmp 2f
1: call _do_wp_page //调用写保护处理函数
2: addl $8,%esp //丢弃压入栈的两个参数,弹出栈中寄存器并退出中断
pop %fs
pop %es
pop %ds
popl %edx
popl %ecx
popl %eax
iret
当错误码存在标志P为1时,会去调用do_wp_page来处理写时复制,不然就去调用do_no_page来处理缺页中断
do_wp_page写时复制
do_wp_page先判断CPU控制寄存器CR2给出的引起页面异常的线性地址在什么范围中,接着调用un_wp_page来处理解除页面写保护,这个是核心函数,其参数是发生异常的地址(逻辑地址)的页表项地址
// /mm/memory.c
//执行共享页面的写保护页面处理
void do_wp_page(unsigned long error_code,unsigned long address)
{
//先判断CPU控制寄存器CR2给出的引起页面异常的线性地址在什么范围中
//如果address小于TASK_SIZE(0x4000000,即64MB),表示异常页面位置在内核或任务0和任务1所处
//的线性地址范围内
if (address < TASK_SIZE)
printk("\n\rBAD! KERNEL MEMORY WP-ERR!\n\r");
if (address - current->start_code > TASK_SIZE) {
printk("Bad things happen: page error in do_wp_page\n\r");
do_exit(SIGSEGV);
}
#if 0
//如果线性地址位于进程的代码空间中,则终止执行程序。因为代码是只读的
if (CODE_SPACE(address))
do_exit(SIGSEGV);
#endif
//调用un_wp_page() 来处理取消页面保护,需要先计算出发生异常的地址(逻辑地址)的页表项地址,来作为参数
un_wp_page((unsigned long *)
(((address>>10) & 0xffc) + (0xfffff000 &
*((unsigned long *) ((address>>20) &0xffc)))));
}
//解除写保护,用于页异常中断过程中写保护异常的处理(写时复制!!!)
void un_wp_page(unsigned long * table_entry)
{
unsigned long old_page,new_page;
old_page = 0xfffff000 & *table_entry;//发生异常的页面物理地址
if (old_page >= LOW_MEM && mem_map[MAP_NR(old_page)]==1) {//如果是主内存且没有被共享过
*table_entry |= 2; //直接修改页表项属性,为可读可写
invalidate();//刷新缓存
return;
}
if (!(new_page=get_free_page())) //申请内存
oom(); //显示内存不够
//到这,说明内存共享
if (old_page >= LOW_MEM)
mem_map[MAP_NR(old_page)]--;//页面引用次数-1
copy_page(old_page,new_page); //复制页面
*table_entry = new_page | 7; //并置可读写等标志
invalidate();//刷新缓存
}
un_wp_page主要有2种情况:
- 当发生异常的页表项地址,是对应未共享页面(这里表现为页面引用数为1的页),直接修改页表项属性,为可读可写
- 当发生异常的页表项地址,是对应共享页面,将原页面引用次数
-1,会重新申请一个空闲页面,并设置为可读可写,同时把这个新页面映射到原来的线性地址,把共享页面内容复制过来,使得父子进程各拥有一份自己的物理页面
以上就是写时复制Copy on Write的所有具体操作

do_no_page缺页中断
最后我们再补充一下,调用do_no_page是如何处理缺页中断的:
// /mm/memory.c
//执行缺页处理
void do_no_page(unsigned long error_code,unsigned long address)
{
int nr[4];
unsigned long tmp;
unsigned long page;
int block,i;
struct m_inode * inode;
//先判断CPU控制寄存器CR2给出的引起页面异常的线性地址在什么范围中
if (address < TASK_SIZE)
printk("\n\rBAD!! KERNEL PAGE MISSING\n\r");
if (address - current->start_code > TASK_SIZE) {
printk("Bad things happen: nonexistent page error in do_no_page\n\r");
do_exit(SIGSEGV);
}
//获取页目录项值
page = *(unsigned long *) ((address >> 20) & 0xffc);
if (page & 1) {
page &= 0xfffff000; //页表地址
page += (address >> 10) & 0xffc; // 页表项指针
tmp = *(unsigned long *) page; // 页表项内容
if (tmp && !(1 & tmp)) { //页表项对应的页面不在内存中,从swap分区加载
swap_in((unsigned long *) page); //从交换设备读页面
return;
}
}
address &= 0xfffff000; // address处缺页页面地址
tmp = address - current->start_code; // 缺页页面对应逻辑地址
//计算出在该inode中需要读的block号(磁盘设备)
if (tmp >= LIBRARY_OFFSET ) {
inode = current->library;
block = 1 + (tmp-LIBRARY_OFFSET) / BLOCK_SIZE;
} else if (tmp < current->end_data) {
inode = current->executable;
block = 1 + tmp / BLOCK_SIZE;
} else {
inode = NULL;
block = 0;
}
//若是进程访问其动态申请的页面或为了存放栈信息而引起的缺页异常,则直接申请一页物理内存
//页面并映射到线性地址address处即可
if (!inode) {
get_empty_page(address);
return;
}
// 尝试逻辑地址tmp处页面的共享
if (share_page(inode,tmp))
return;
if (!(page = get_free_page()))//尝试申请一页物理内存
oom();
/* remember that 1 block is used for header */
//第一个block空出来不用,所以block要从1开始算起;4是因为,一页内存需要读4个数据块
for (i=0 ; i<4 ; block++,i++)
nr[i] = bmap(inode,block);
bread_page(page,inode->i_dev,nr); //把这4个逻辑块读入到物理页面page
//下面对超过end_data区域的数据清0
i = tmp + 4096 - current->end_data; //超出的字节长度值
if (i>4095) //离末端超过1页则不用清零
i = 0;
tmp = page + 4096; // tmp指向页面末端
while (i-- > 0) { //页面末端i字节清零
tmp--;
*(char *)tmp = 0;
}
//最后把引起缺页异常的一页物理页面映射到指定线性地址address处
if (put_page(page,address))
return;
//否则就释放内存页,显示内存不够
free_page(page);
oom();
}
我们知道在Linux0.12中,管理内存是通过线性地址来充当"桥梁",沟通逻辑地址和实际的物理地址。也就是内核的内存管理让程序直接与虚拟内存进行交互,这样的好处是,内核可以"欺骗"程序,给它一段连续的"内存",而且还足够的大,让它能够自由奔放地执行下去。其实这里的"内存"是虚拟内存,而不是实际物理内存;虚拟内存另一方面让程序与程序之间的地址进行隔离,避免了一个程序的出错导致整个系统全部死机,也保护了用户的心智

那么操作系统又是怎么将虚拟内存和实际物理内存联系起来的呢?只需要对照即可,最简单的是将虚拟内存的每一Byte地址都对应到物理内存的地址上,但会造成对照表所占空间过大费;CPU采用分页机制,每页单位4K,只需将虚拟内存页映射到对应的物理内存页即可,再通过多级页表的方式,可以大幅度节约对照表的所占空间,还不影响CPU的寻址能力
这样就会存在一种情况,虚拟内存没有与实际内存建立映射关系的问题,比如Linux0.12给每个进程分配了64M的虚拟内存空间,但实际能操作的就16M。这个时候会产生缺页中断,调用do_no_page来处理缺页的情况,来按需加载内存
Linux0.12是写时复制,虚拟内存并不能与实际内存建立完全的映射关系,需要用的时候才实际分配物理内存
do_no_page它首先判断指定的线性地址在一个进程空间中相对于进程基址的偏移长度值。如果它大于代码加数据长度,或者进程刚开始创建,则立刻申请1页物理内存,并映射到进程线性地址中,然后返回;接着尝试进行页面共享操作,若成功,则立刻返回
若共享操作不成功,则申请1页内存,并根据线性地址和inode可以计算出需要读的磁盘block号,从磁盘中读入对应的1页(4块)的信息
在分配物理内存,但可用内存不足时,将暂时不用的内存数据先放到磁盘上,让有需要的进程先使用,等进程再需要使用这些数据时,再将这些数据加载回内存中,这就是内存交换swap
若加入该页信息时,指定线性地址+1页长度超过了进程代码加数据的长度,则将超过的部分清零。最后将该页映射到指定的线性地址处
本文到这里就结束啦,感觉你的阅读
点赞在看就是对笔者最好的催更,我们下期再见~
参考资料:
https://elixir.bootlin.com/linux/0.12/source/kernel/fork.c
英特尔® 64 位和 IA-32 架构开发人员手册:卷 3A-英特尔®
《Linux内核完全注释5.0》
https://mp.weixin.qq.com/s/X3FmlsrZqf6b7We8UHOjfw
https://mp.weixin.qq.com/s/FBoXc4YeLfejBJx8ylvDNg
本文首发于公众号「小牛呼噜噜」,扫码关注,即可品读更多精彩文章
