算法炼金术: 什么是DeepSeek?
DeepSeek(深度求索)是中国一家专注于实现通用人工智能(AGI)的人工智能公司,总部位于杭州。公司由量化资管巨头幻方量化的创始人梁文锋于2023年创立,致力于探索AGI的本质并推动技术的持续进步。

DeepSeek V3的核心是一个先进且强大的大语言模型LLM,它能够理解自然语言并生成高质量的文本内容,无论是为你答疑解惑,还是妙笔生花撰写文章,又或是应对复杂的逻辑推理,DeepSeek 都游刃有余,毫不费力。
这里得必须介绍一下deepseek的创始人,梁文锋。1985 年,梁文锋出生于广东湛江,17 岁时就凭借优异的成绩考入浙江大学电子信息工程专业,年少有为,天赋异禀。

早在 2008 年起,它便对金融市场怀揣着浓烈热忱,同年开始探索机器学习在量化交易中的应用,展现出了对新兴技术敏锐的洞察力。2015 年,他创立了幻方科技,专注于量化投资领域。在他的带领下,幻方科技短短几年时间就做到了千亿规模,成为了行业内的佼佼者
时间来到 2023 年,梁文锋再度做出大胆且极具前瞻性的决策,毅然进军通用人工智能(AGI)领域,并成功创办 DeepSeek。为给 DeepSeek 的技术研发配备顶尖硬件支持,他亲率团队日夜攻坚,成功研发出 “萤火一号” 和 “萤火二号” 超级计算机,为后续的技术飞跃筑牢了坚不可摧的根基 。
2024 年,DeepSeek 发布了 DeepSeek - V2,一经推出,就震惊了整个行业,让人们看到了中国 AI 技术的崛起。2025 年 1 月,DeepSeek - R1 重磅发布,其性能甚至超越了美国 OpenAI 的 o1,而且完全开源。这一消息在全世界范围内引发了轩然大波,真是太牛了
核心技术特点
- AGI 探索征程:将洞察 AGI 本质奉为核心使命,凭借前沿技术一马当先,勇攀智能科技高峰。
- 核心技术攻坚:牢牢锚定大模型、内容生成、智能代理等关键领域,全力助推 AI 迈向更高智能层级,重塑行业格局。
- 高效训练革新:凭借自主研发的先进技术,大幅削减大模型训练成本,同时显著提升训练效率,为行业发展注入强劲动力。
- 多模态能力拓展:全面支持文本、图像、音频等多元内容形式的生成,打破信息媒介壁垒,开启创意无限可能。
- 安全可控保障:将 AI 伦理与安全性置于首位,全方位严格把控,确保技术稳定可靠,为社会发展筑牢坚实根基 。
主要产品
- DeepSeek-R1:智能助手,支持复杂任务处理(如数据分析、代码生成)。
- DeepSeek-Chat:对话式AI,覆盖办公、教育、创意等场景,提供高效交互体验。
- 企业级解决方案:为金融、医疗等行业提供定制化AI服务。
功能与特点
DeepSeek 作为一款面向多场景的智能助手,其核心功能设计紧密围绕用户实际需求,在以下方面表现突出:
智能对话:上下文理解与动态交互
- 多轮对话能力:支持连续提问和上下文关联(例如追问细节时无需重复背景信息)。
- 场景适配:根据对话场景(如教育、职场)自动调整回答风格,提供专业或口语化回复。
- 意图识别:精准捕捉用户隐含需求(例如用户问“今天适合穿什么?”会结合天气、场合综合回答)。
准确翻译:跨语言与领域专业化
- 多语言覆盖:支持主流语言互译(中、英、日、韩等),并针对小语种优化。
- 行业术语库:内置金融、法律、医疗等专业术语库,避免通用翻译的歧义(例如“cell”在生物和IT领域的不同译法)。
- 语境感知:结合上下文调整翻译结果(如成语、俚语的本地化表达)。
创意写作:激发灵感与风格定制
- 多样化创作:生成诗歌、故事、广告文案、剧本等,支持设定风格(如“鲁迅风格短篇小说”)。
- 逻辑连贯性:确保长文本(如小说章节)的情节连贯和角色一致性。
- 反馈迭代:根据用户修改意见实时调整内容(例如“让对话更口语化”)。
高效编程:代码生成与问题排查
- 全栈支持:生成 Python、Java、JavaScript 等主流语言的代码片段,注释清晰。
- Debug 辅助:通过报错信息定位问题,提供修复建议(如内存泄漏优化方案)。
- 代码解释:对复杂代码逐行注释,帮助理解第三方库或算法逻辑。
智能解题:跨学科分析与步骤拆解
- 理科应用:解数学题(如微积分)、物理公式推导,展示完整计算过程。
- 文科推理:分析历史事件因果关系、哲学论点逻辑链。
- 教育分级:根据用户知识水平调整解题深度(如面向学生提供基础版解释)。
文件解读:结构化分析与关键提取
- 多格式解析:支持 PDF、Word、Excel 等文件内容总结(如提取合同核心条款)。
- 数据可视化:将表格数据自动转化为图表,或生成分析报告。
- 问答交互:针对长文档内容直接提问(例如“这份财报中净利润增长率是多少?”)。
知识问答与搜索增强(RAG)
DeepSeek 可能集成了 检索增强生成(Retrieval-Augmented Generation, RAG),用于提升知识问答的准确性:
- 知识问答(QA):用户可以提问各种知识性问题,DeepSeek 基于其大规模预训练知识库生成答案。
- 搜索增强(RAG):结合搜索引擎,在回答问题时参考最新的网页、文献、论文,提高答案的实时性和可靠性。
- 代码搜索:开发者可以输入代码问题,DeepSeek Coder 结合代码仓库(如 GitHub、Stack Overflow)返回最佳代码示例。
技术原理
接下来分享一下,deepseek v3论文里的技术原理图 如下
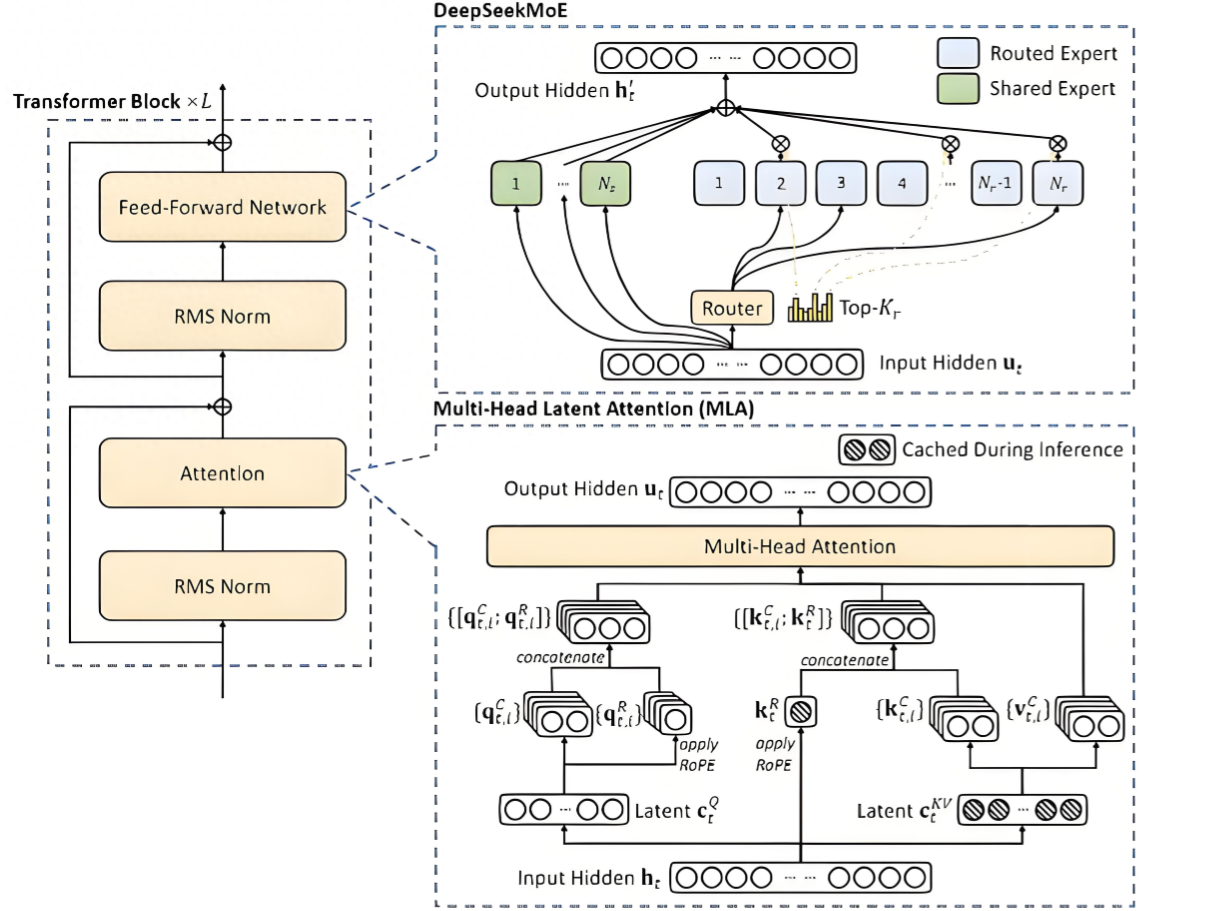
接下来我们通俗一点来解释deepseek的技术原理,尽量不用专业术语:
1. 核心:一个超级会学习的“大脑”
- 基础积木:DeepSeek 的核心是一个由海量书籍、文章、对话记录训练出的“大脑”(大语言模型)。就像人类通过阅读学习知识,它通过分析这些数据学会了文字规律、逻辑推理等能力。
- 特殊技能:这个大脑的特别之处在于,它能把学到的知识拆解成无数个小碎片(比如“猫的特征”“编程语法规则”),并记住这些碎片之间的关系。当遇到问题时,它能快速组合相关碎片给出答案。
2. 如何实现“深度思考”?
想象你在玩拼图:
- 第一步:收集碎片
当你提问时,DeepSeek 会先拆解问题(比如“为什么天空是蓝色的?”会分解为“光的散射”“大气层成分”等碎片)。 - 第二步:拼图验证
它会尝试多种组合方式(不同科学原理的组合),并通过内部“模拟实验”(数学计算)验证哪种组合最合理。 - 第三步:自我检查
如果发现某块“拼图”有问题(比如逻辑矛盾),它会自动替换成其他碎片重新组合,直到答案可靠。
3. 为什么能翻译/写作/编程?
- 翻译:它的大脑里存储了多种语言的平行碎片(比如中文“苹果”和英文“apple”对应同一物体),还能根据上下文选择正确含义(比如“苹果公司”和“吃苹果”的不同翻译)。
- 创意写作:它学过大量小说、诗歌,知道“故事需要开头→冲突→结局”的结构,还能模仿不同作家的“碎片组合风格”(比如鲁迅的冷峻 vs 金庸的武侠)。
- 编程:它的大脑里有一本“代码字典”,知道“print() 代表输出”“for 循环的语法规则”,并能按照你描述的需求拼接代码块。
4. “联网搜索”怎么工作?
- 外接U盘:DeepSeek 的基础大脑像一台不联网的电脑,存储了训练时学的知识。而“联网搜索”功能相当于给它插了一个实时更新的U盘,遇到新问题时(比如“今天杭州天气”),它会:
① 快速上网抓取最新数据
② 用原有大脑判断哪些信息可靠
③ 把筛选后的信息整合进答案
5. 为什么反应这么快?
- 高速公路设计:DeepSeek 的大脑内部有特殊“高速公路”(模型架构优化),能让信息传递路径最短。比如你问“1+1=?”,它不会绕路思考“宇宙起源”,而是直接调用数学规则碎片。
- 压缩技术:就像把高清电影转成小文件却不模糊,它用特殊方法精简了大脑体积,但保留了关键能力,所以回答速度堪比人类对话。
我们可以发现,DeepSeek就像一位聪明的拼图匠——既会快速翻找库存,又能随时抓取新碎片,再用逻辑严丝合缝拼出精准答案。
核心架构
DeepSeek 基于Transformer 架构(自然语言处理的行业标准),但针对性能与效率进行了多项改进:
- 稀疏注意力机制:减少模型计算量,仅关注关键信息(类似人类“选择性阅读”)。
- 混合专家模型(MoE):将大模型拆分为多个“小专家”,动态调用相关专家处理不同任务(例如调用“编程专家”生成代码,调用“翻译专家”处理多语言)。
- 层级化结构:底层学习通用语言规律(如语法),高层专注复杂推理(如数学推导)。
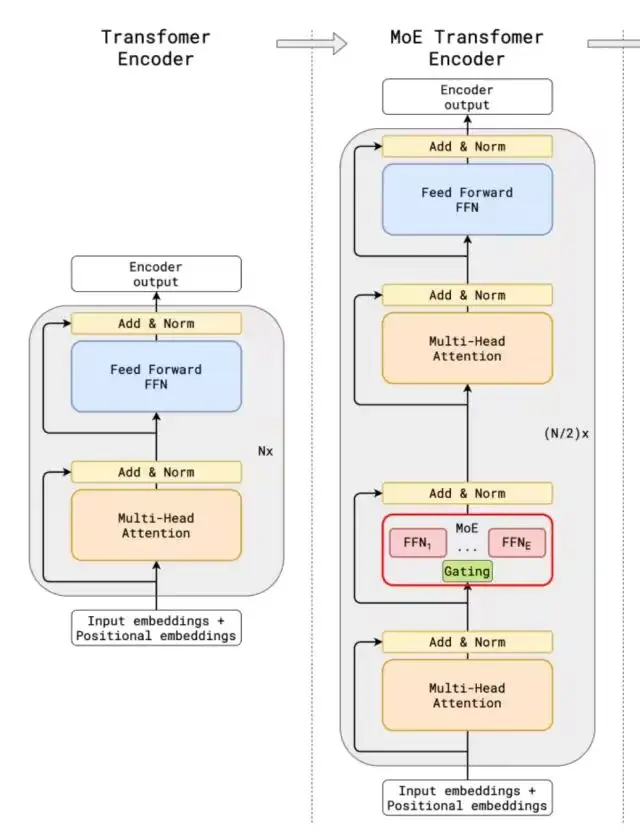
高效的训练策略
- 数据引擎
使用高质量多模态数据(文本、代码、数学公式等),并通过自研清洗工具过滤噪声数据。
引入课程学习(Curriculum Learning):像人类学习一样,先学简单任务(如单词拼写),再逐步挑战复杂任务(如代码生成)。
- 分布式训练优化
采用 3D 并行技术(数据并行、模型并行、流水线并行),将千亿参数模型拆分到数千张 GPU 上训练。
自研 Checkpoint 压缩技术,减少训练中断恢复时间。
- 知识蒸馏
简单来讲,知识蒸馏就如同老师向学生传授知识,是将大模型所掌握的知识传递给小模型的过程。以 DeepSeek - R1 为例,它借助知识蒸馏技术,把长链推理模型具备的能力,悉心 “教授” 给标准的 LLM。如此一来,标准 LLM 的推理能力便得到显著提升,如同学生在老师教导下实现了学业上的进步 。
- 核心算法DualPipe-创新流水线并行算法
DeepSeek-V3应用了16路流水线并行(PP),跨越8个节点的64路专家并行(EP),以及ZeRO-1数据并行(DP)。
与现有的流水线并行方法相比,DualPipe的流水线气泡更少。同时重叠了前向和后向过程中的计算和通信阶段,解决了跨节点专家并行引入的沉重通信开销的挑战。

为何如此惊艳?
DeepSeek 的模型在性能上接近美国顶尖AI模型,同等算力下训练速度提升 40%+。
但研发成本极低,DeepSeek-R1模型的训练成本仅为560万美元,远低于美国科技巨头数亿美元乃至数十亿美元的投入。
这种以低成本实现高效运作的创新模式,犹如一记重锤,直接对美国凭借高算力投入、海量资本堆砌所构建的人工智能护城河模式发起冲击。
长久以来,美国在科技行业稳坐 “霸主” 之位,尽享领先优势,而此番冲击,让其 “霸主地位” 遭遇前所未有的严峻挑战,行业格局正面临重新洗牌的巨大变数。
应用场景
这里举3个群体使用实例
- 学生群体:利用工具助力解数学难题,高效生成论文提纲,实现文献快速阅读,学业之路更顺畅。
- 开发者们:借助工具完成代码生成,轻松解读技术文档,获取 API 调用示例,开发工作更高效。
- 商务人士:依靠工具实现多语言合同精准翻译,深入分析竞品报告,条理清晰整理会议纪要,商务事务更专业 。
还有许多场景,比如办公:自动化文档处理、会议纪要生成;教育:个性化学习辅导、智能题库;娱乐:创意内容生成(如剧本、设计)
最后: 如何使用
打开 DeepSeek,聊天界面提供了三种模式——基础模型、深度思考(R1)和联网搜索,可根据不同场景和需求,灵活选用
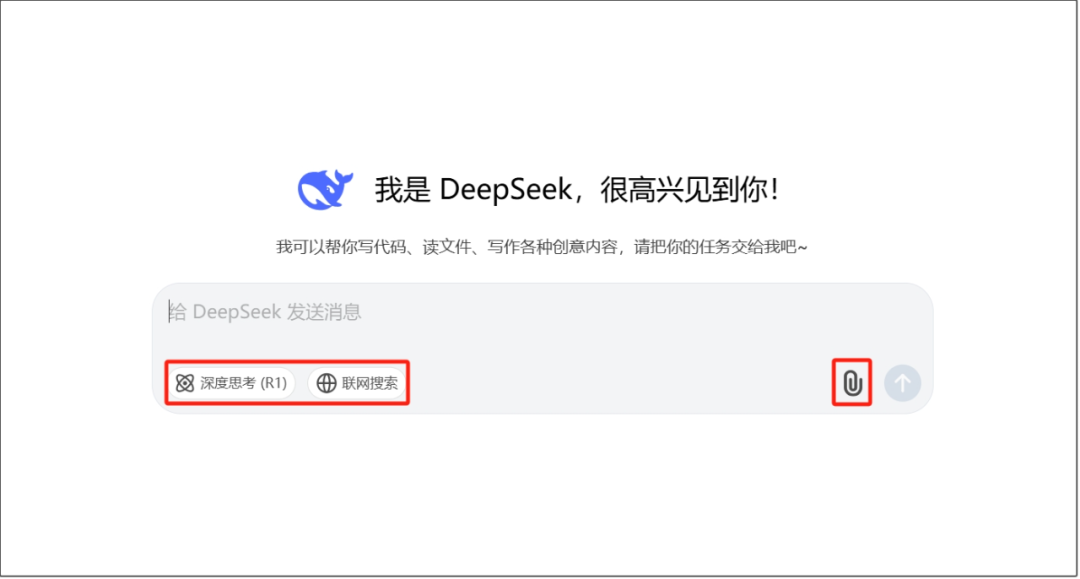
其中“深度思考”与“联网搜索”的核心差异点:
- 深度思考
- 多角度推理:对复杂问题拆解为子问题,分步骤验证假设(例如辩论话题的正反论证)。
- 知识关联:调用跨领域知识库(如将生物学原理应用于商业案例分析)。
- 自我纠错:在回答过程中检测逻辑漏洞并自动修正。
- 联网搜索
- 实时信息获取:通过接入互联网获取最新的知识库(例如回答“今日国际油价”)。
- 权威源引用:优先抓取学术论文、政府网站等可靠信息源。
- 多源对比:呈现不同观点或数据,辅助用户判断(如对比多家机构对经济趋势的预测)。
在这篇文章里,我们给大家详细讲讲 DeepSeek 究竟是什么。从它具备的功能特点,到背后的技术原理、核心架构,还有实际的应用场景,都会用尽量简单易懂的方式进行科普。由于时间比较紧张,要是不小心有什么遗漏或错误的地方,还请大家多多包涵。
参考资料:
- deepseek v3论文
- https://www.cnblogs.com/shanren/p/18707493
最后速来关注我们的公众号:小牛呼噜噜!无需繁琐步骤,无任何套路,只需在后台回复deepseek,精心整理的 DeepSeek 全套资料即刻免费到手,带你轻松解锁 DeepSeek 的奥秘
